详细介绍

达尔文大模型:赛灵力生物AI技术新突破
达尔文大模型是由赛灵力开发的一款专注于生物领域的AI工具,旨在通过复杂系统建模和多模态数据处理,推动生物学研究和产业应用的发展。该模型不仅为生物学研究提供深入的分析和建模支持,还通过互动和口播数字人SaaS平台,扩展了AI技术在内容生产和品牌营销中的应用。
核心优势:
- 多模态数据处理: 支持文本、图像、声音等多种数据类型,实现全面的数据分析。
- 复杂系统建模: 专为生物领域复杂系统设计,提供精准的模型构建。
- 深入研究支持: 为生物学研究提供数据分析和模型构建的强大工具。
- 产业应用优化: 帮助生物产业企业提升研发效率,推动产品创新。
主要功能:
- 生物系统分析: 深入分析生物系统,构建精确模型。
- 研究支持: 提供生物学研究所需的数据支持和模型分析。
- 产业应用: 助力生物产业企业在研发和生产中应用AI技术。
- 互动数字人SaaS平台: 创建和管理虚拟形象,提升品牌推广和客户互动。
- 口播数字人SaaS平台: 专注于口播内容的数字人创建和管理,提高内容生产效率。
应用场景:
- 生物学研究: 研究人员利用达尔文大模型对特定生物系统进行建模和分析。
- 生物技术公司: 优化产品研发流程,提升研发效率。
- 品牌营销: 通过互动数字人SaaS平台创建虚拟形象,增强品牌推广效果。
- 教育领域: 使用口播数字人SaaS平台创建教学辅助材料,提升教学质量。
总结:
达尔文大模型是赛灵力在生物AI领域的一项重大突破,通过先进的数据处理和模型分析技术,为生物学研究和产业发展提供了强有力的支持。其附带的数字人SaaS平台进一步扩展了AI技术在内容生产和品牌营销中的应用,使得达尔文大模型成为一个多功能、高效率的AI解决方案。
查看更多
最新文章
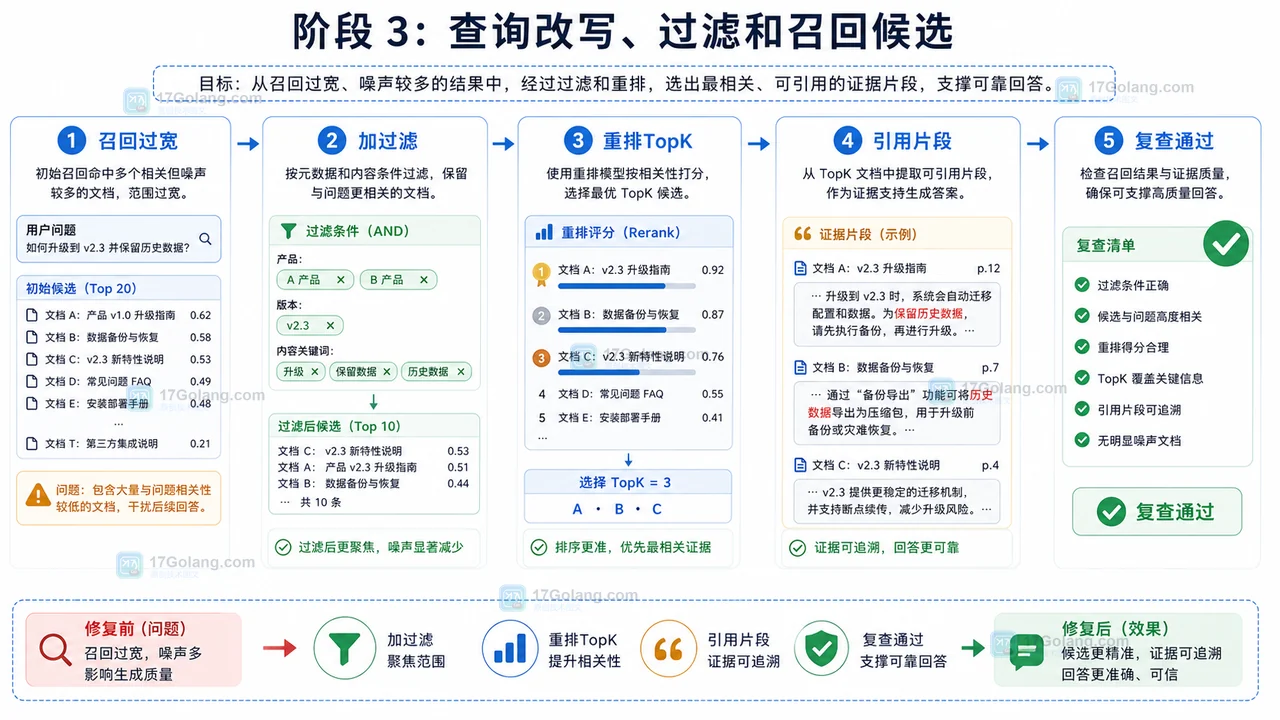
AI 知识库检索召回工作流:从文档切分到重排和证据引用
本文整理一套 AI 知识库检索召回工作流,从文档清洗、切分、向量入库、查询改写、过滤重排到证据引用和复查
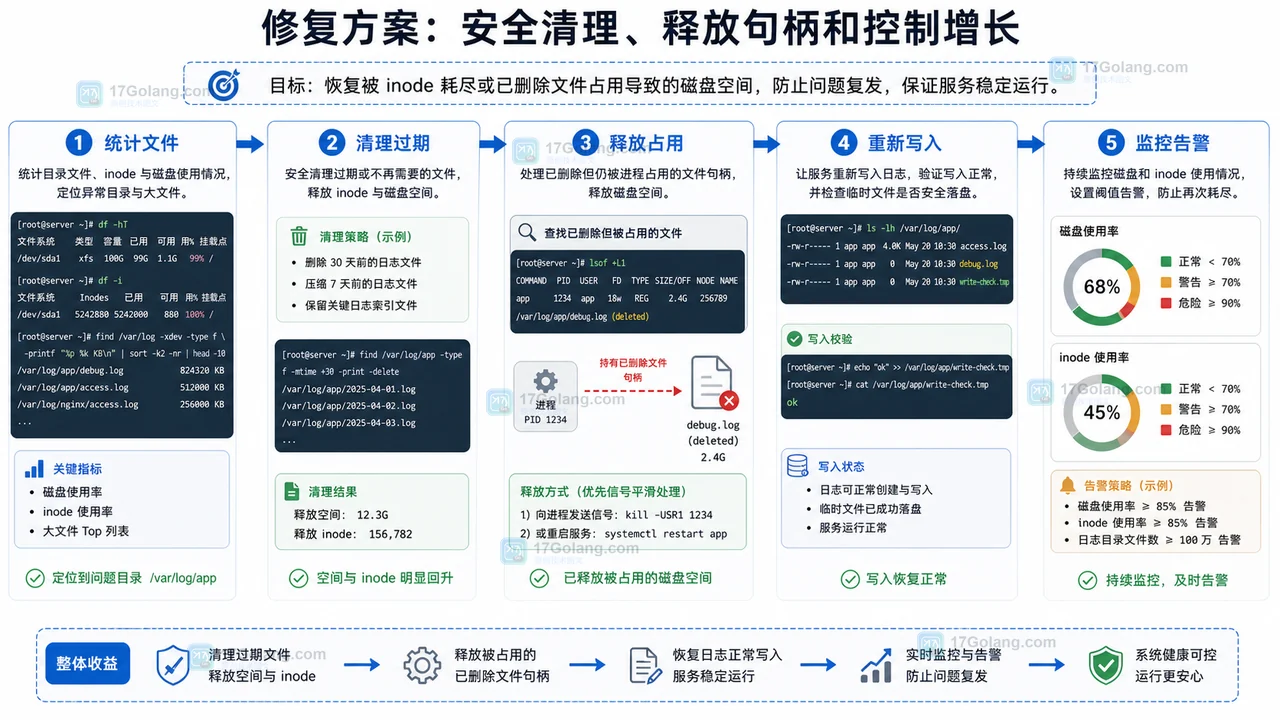
Linux 磁盘还有空间却写入失败排查:从 inode 到已删除文件占用
本文从 Linux 写文件提示 No space left on device 但 df -h 仍有空间
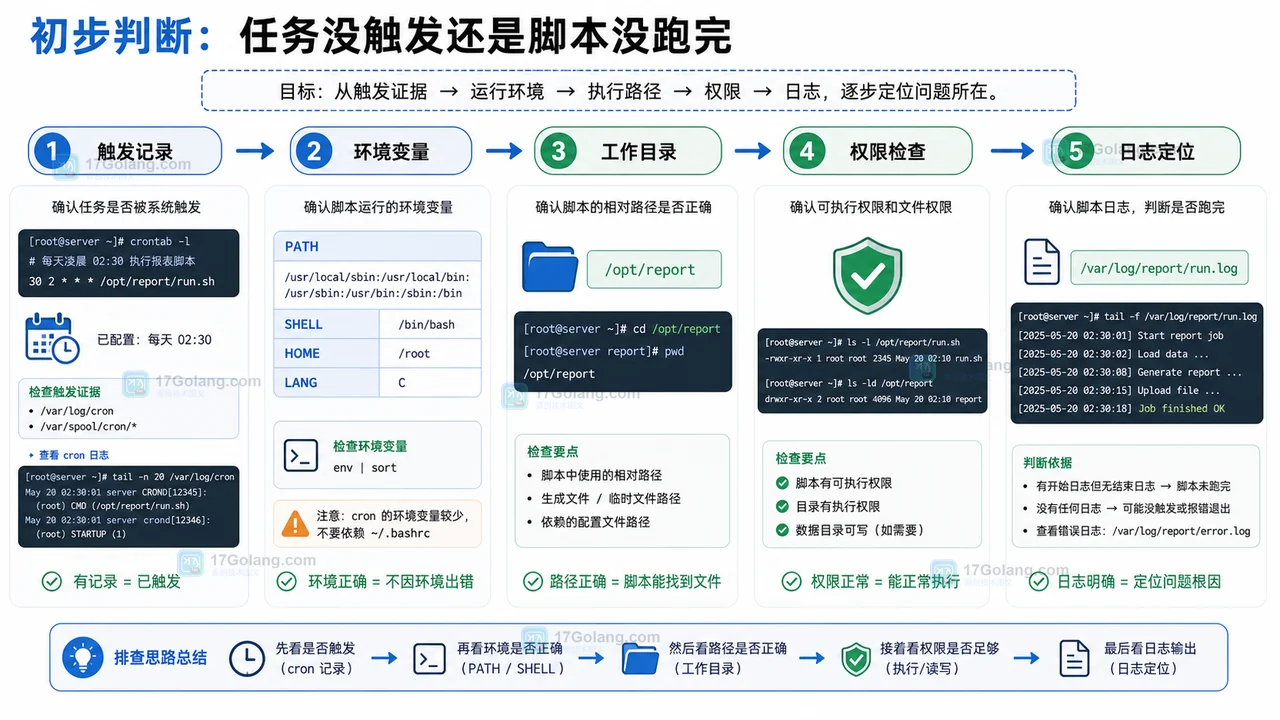
Linux crontab 定时任务不运行排查:从 PATH 到工作目录和日志
本文从 crontab 定时任务没有按时运行的现象出发,按触发记录、PATH、工作目录、权限、日志和并发
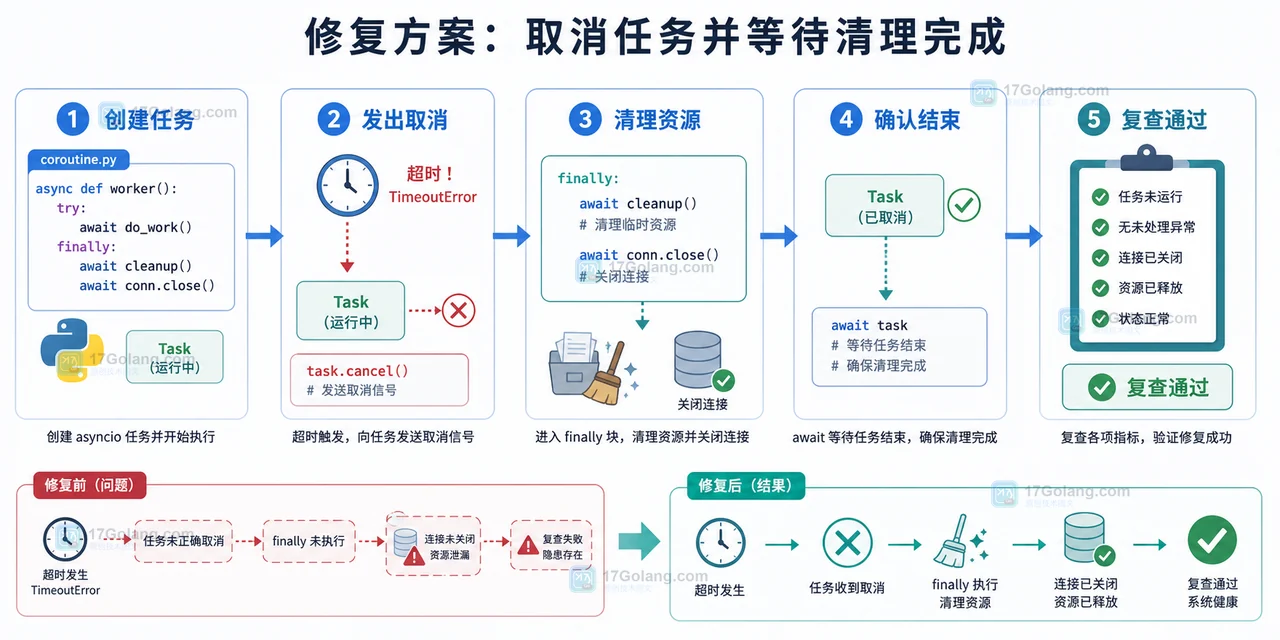
Python asyncio 超时后任务还在跑排查:从 wait_for 到取消清理
本文从一个 asyncio 超时后后台任务仍在继续的现象出发,排查 wait_for、shield、取消
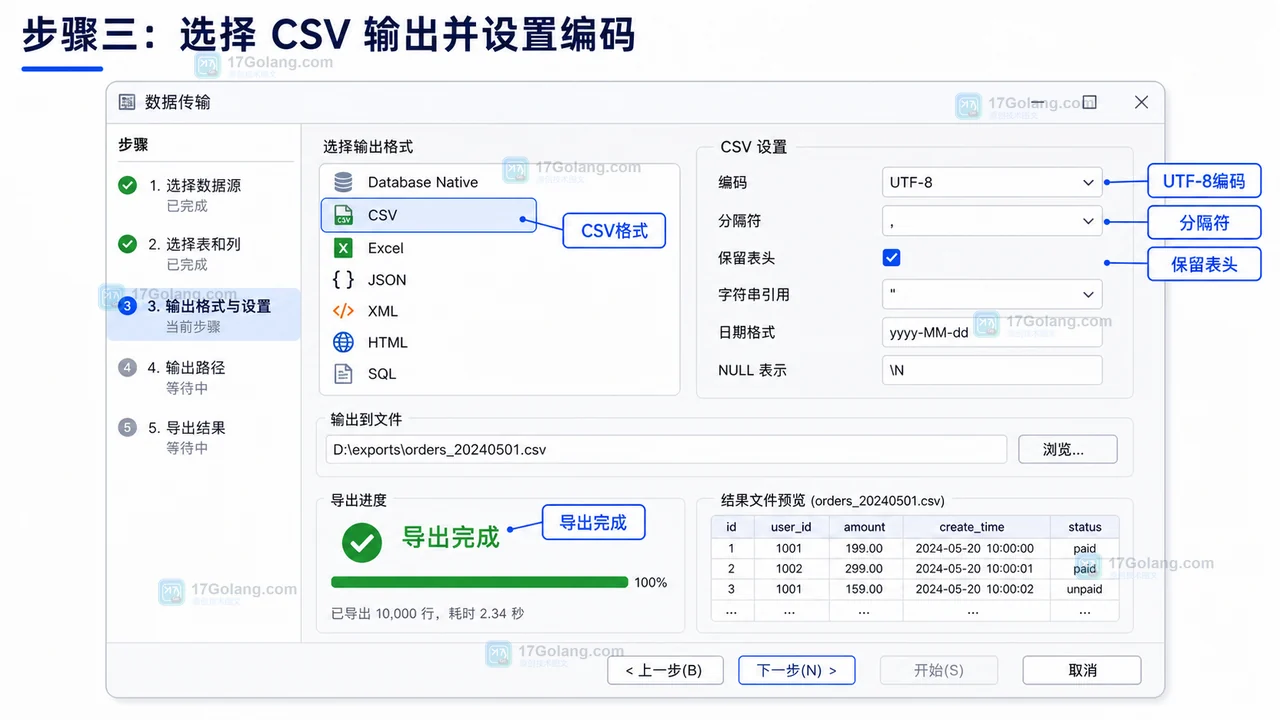
DBeaver 导出查询结果为 CSV:从结果集到编码检查
本文按 DBeaver 实际界面操作,演示从 SQL Editor 运行查询、在结果集面板启动 Data
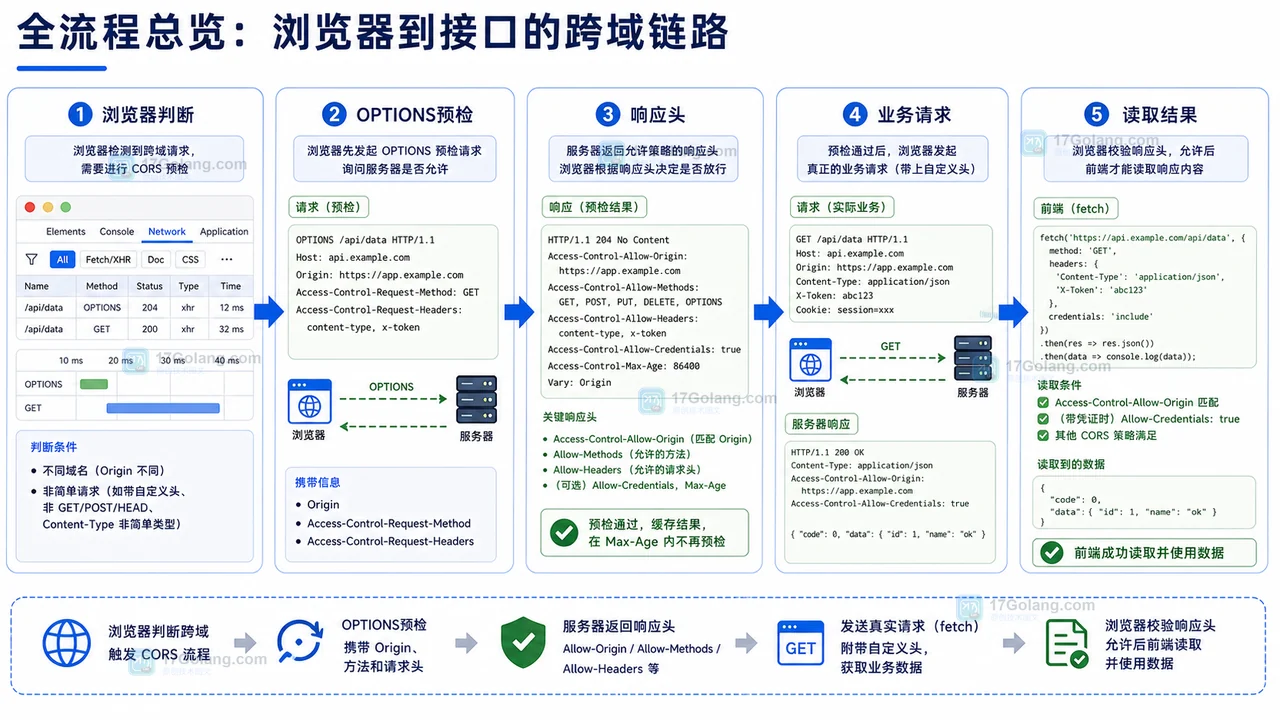
前端 CORS 预检失败排查流程:从请求头到网关响应
本文整理一套前端 CORS 预检失败的排查流程,从浏览器请求头、OPTIONS 预检、服务端响应、网关转



