详细介绍
Seed-VC:零样本声音转换模型,开启音色转换新时代
Seed-VC是一款革命性的零样本(zero-shot)声音转换模型,专为声音合成和编辑领域设计。它能够将源音频的声音特征转换为目标音色,而无需在目标音色上进行显式训练。这一技术的突破,为声音转换提供了全新的可能性。
核心优势
- 零样本学习: Seed-VC通过零样本学习技术,无需特定目标音色样本即可进行高效的声音转换。
- 卓越性能: 与其他模型相比,Seed-VC在声音转换任务上展现出卓越的性能,确保转换后的音频质量。
- 多样性支持: 模型能够处理多种声音和音色,提供丰富的转换选项,满足不同用户的需求。
主要功能
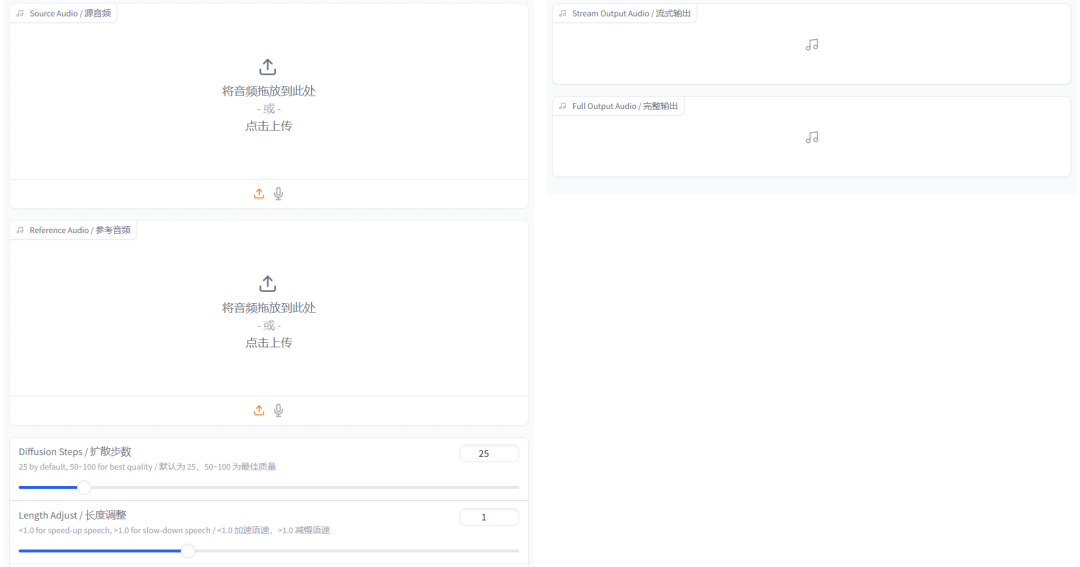
- 声音转换: 利用音色提示(timbre prompt),将源音频的音色转换为目标音色,实现高质量的音色转换。
- 音频处理: 对音频进行处理,以实现不同音色之间的转换,提升音频编辑的灵活性。
- 模型比较: 通过与其他声音转换模型的比较,展示Seed-VC的性能优势,帮助用户选择最佳工具。
使用示例
在我们的网页上,用户可以体验不同模型处理后的音频样本。通过表格展示源音频、音色提示以及Seed-VC和其他模型转换后的音频。用户只需点击音频元素,即可听取转换效果,评估Seed-VC的性能表现。
总结
Seed-VC作为一款创新的声音转换工具,通过零样本学习技术,实现了无需特定目标音色样本的高质量声音转换。其卓越的性能和处理多样性声音的能力,为声音合成和编辑提供了新的可能性。用户可以通过网页上的音频样本,直观地体验和比较Seed-VC与其他模型的转换效果,选择适合自己的声音转换解决方案。
查看更多
最新文章
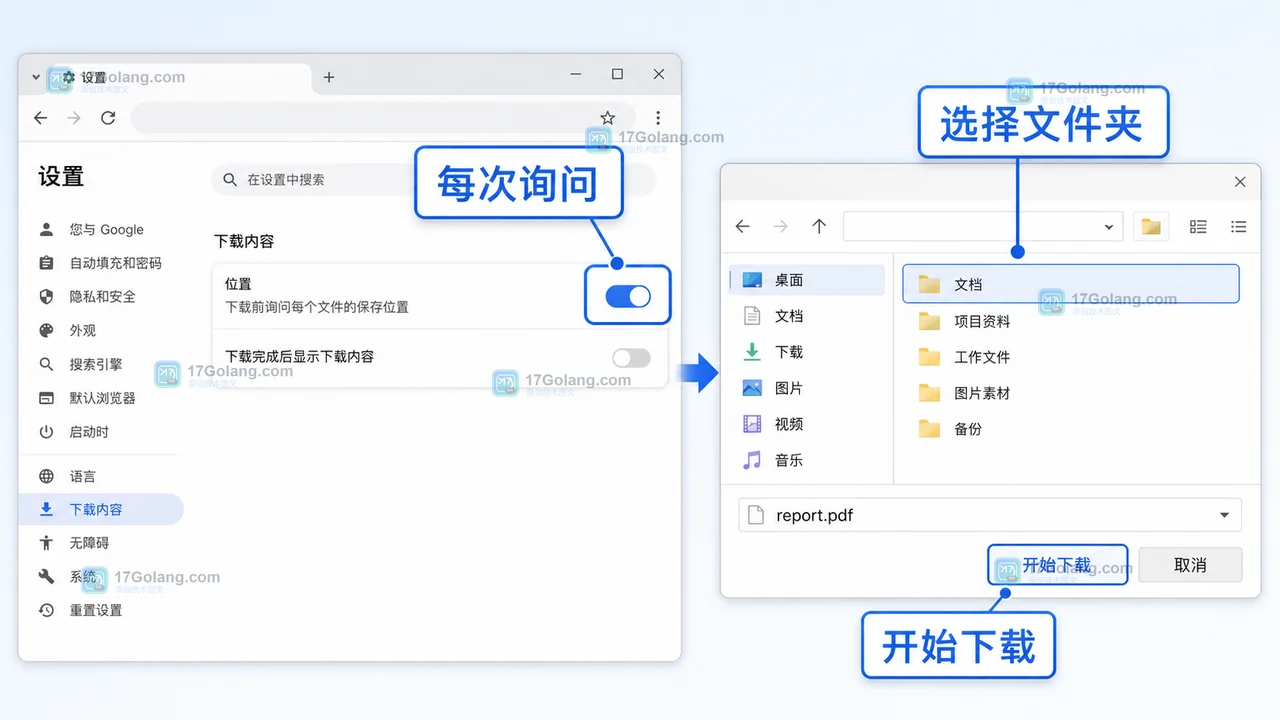
Chrome 下载总存错文件夹怎么办:下载位置和每次询问这样设置
Chrome 下载文件总是落到不方便找的文件夹,通常不是下载失败,而是默认下载位置或“每次询问保存位置”
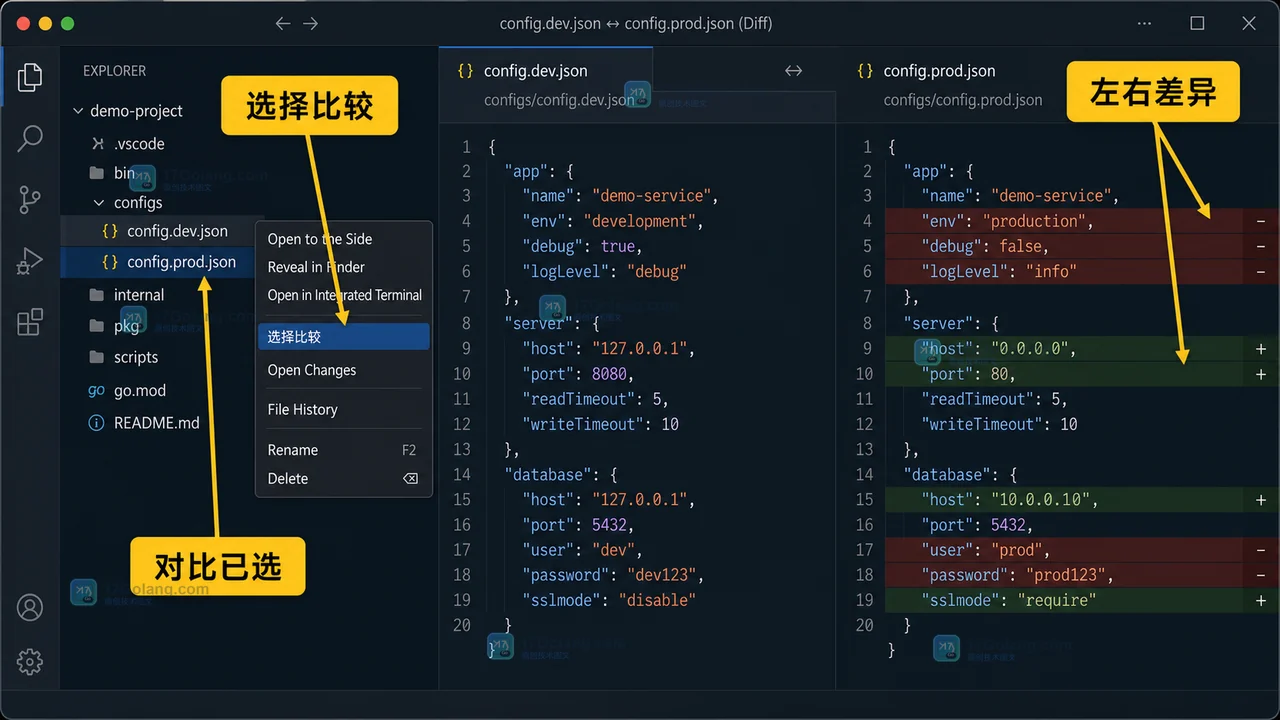
VS Code 怎么比较两个文件:资源管理器与命令面板两种方式
VS Code 内置 Diff 编辑器,不用安装扩展也能比较两个文件、当前文件与已保存版本或剪贴板。本文

燃气报警器响了怎么办?先别开灯,按这个顺序处理
燃气报警器响起时,最怕的是一边找原因一边开关电器。本文根据消防与住建部门公开提示,整理关闭气源、通风、撤

住高层遇到地震怎么办?先就近避险,震后再有序撤离
高层震感明显时,最危险的往往是慌张冲向电梯或阳台。本文依据应急管理与地震部门公开指引,整理震时就近避险、
汽车涉水熄火能二次启动吗?先别打火,按这几步处理
车辆在积水中熄火,反复打火可能扩大损伤,也可能把人留在更危险的位置。本文根据交警与消防公开提示,说明熄火

儿童坐高铁要带身份证吗?免费儿童和优惠票这样准备证件
带孩子坐高铁,证件别只看大人。本文依据铁路运输规程和12306公告,说明免费乘车儿童、儿童优惠票的证件准



